This past weekend was the ever-epic
NCCDC, with the returning champions
UCF taking the cup again!! The NCCDC Red Team truly is the final boss of CCDC, bringing out famous red teamers from across the nation, such as
Mubix,
Nickerson,
Kennedy,
Egyp7,
SciptJunkie,
Cowen,
Scap,
Cmc,
Javier,
Shields,
Ryan,
Leon,
Rhodes,
Heather, and many more! This year,
Alex and I put a ton of prep in for red team infrastructure, tooling, and strategy. We two manned a red cell against eight blue team members and had a really great time in the process. The following is a post mortem for future blue and red teams, in hopes we all continue to push our skills in this game. Alex worked on a ton of red team infrastructure, including our red team scoring server, the borg cluster, a new distributed callback network, and some integrated C&C. I focused on the Windows based dropper for the group, which we wrapped many of the groups'
team-server payloads (for the shell-sherpas of our group) and generally usable host based payloads. I also set up a popular host management framework as a cross-platform, beaconing, C&C infrastructure, an experiment I wanted to try at NCCDC for some time (more on this later)! As only a two man red team, Alex and I, had to divide and conquer, as well as work synergistically. Alex focused on the Linux systems, I focused on the Windows systems, and we met in the middle on web apps and critical servers like the ESXI. While a lot of my writeup will cover the things I saw on those Windows based platforms, the general theory can be applied to all systems.


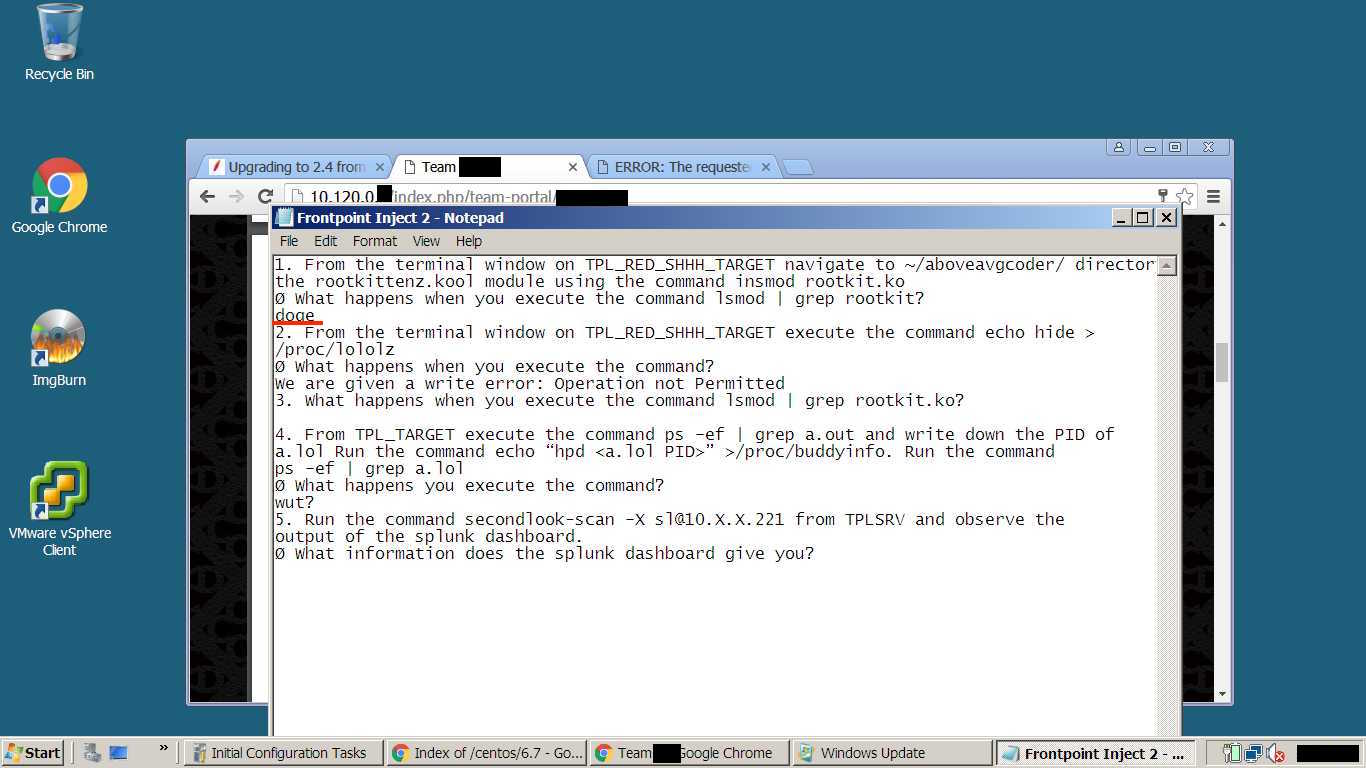
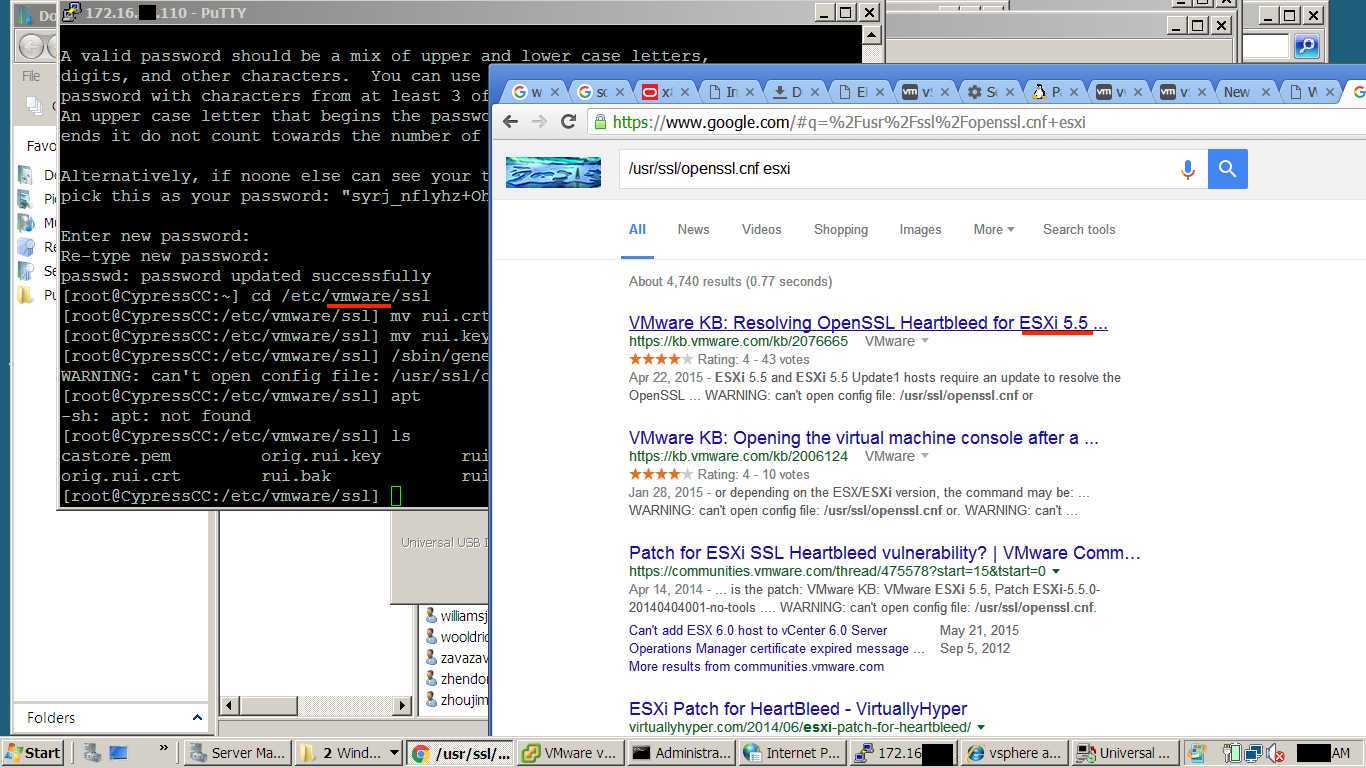
Assume compromise! You have the benefit of knowing the attackers are focused directly on you for the short lifespan of the competition, so you should be extra paranoid when evaluating the legitimacy of your machine's processes. Look for files that have been created or modified since the start of the competition, if it wasn't your team then it was likely the red team! Look at the user's accessing your systems, if it's not the set your team has agreed to use then shut them down! Your provided some really great tools to do this too, things I use all the time on Windows, for example lets look at some of the tools in SysInternals that could help. Set up Sysmon logging for more detailed system execution logs, use autoruns to look for persistence items, use process explorer to find odd process trees and use process monitor to deep dive on what those processes are doing to your system!


It's also important not to administer one critical system from another! If a system is a high value target for us it is much more likely to be compromised than a workstation, especially if that high value system has no real increased security controls. Don't rely on the easy or the default path provided, but reconstruct and administer your environment in an intelligent and secure way to the best of your ability (like when UCF turned a VoIP phone into a firewall 3 years ago). If you absolutely have to use that critical machine to reach the other, attempt to do it with a less privileged user that you've agreed on using. By spying on actions through the domain controller, where many of the service injects were being worked on and people were accessing the various ESXI machines, we were able to use key-logger and screen capture tools to pick up a lot of useful intel, including injects and passwords.


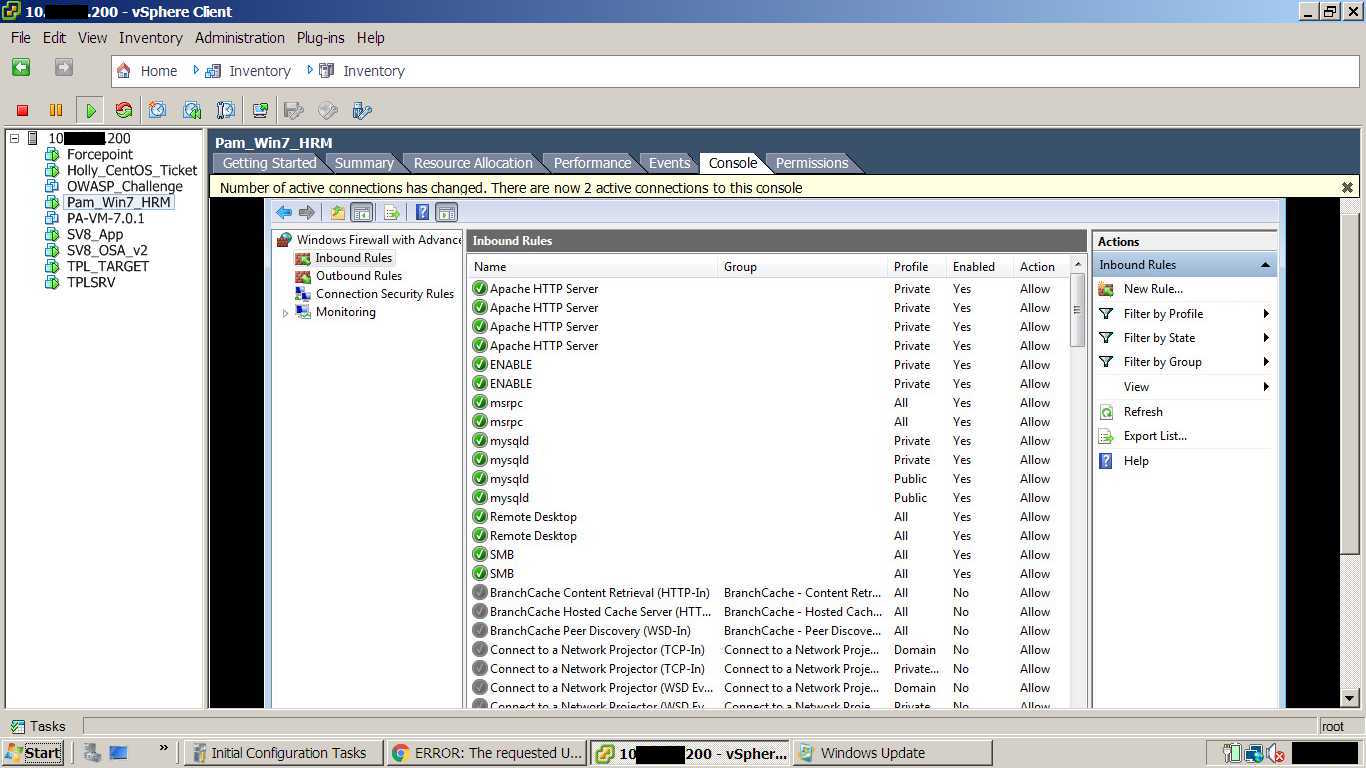
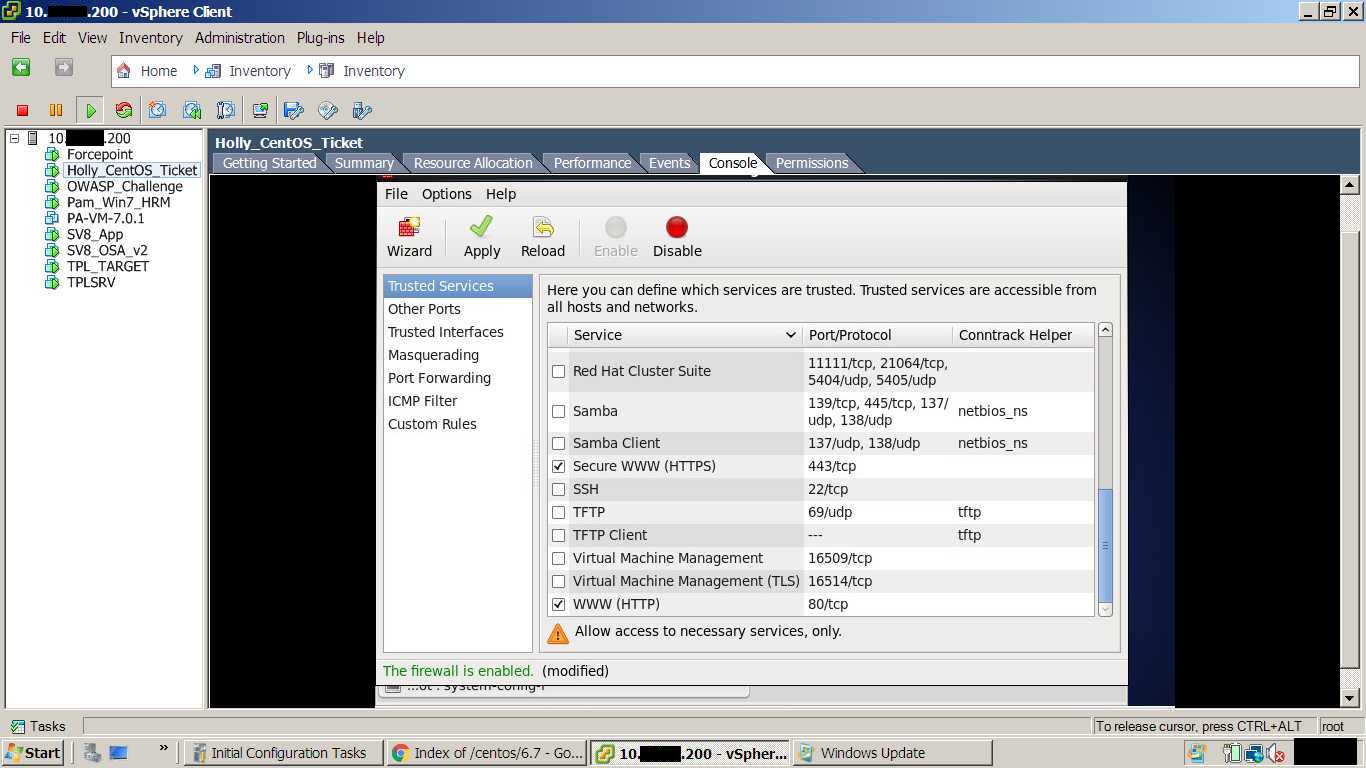
One way to catch on these machines is to monitor your configurations, services and processes. If it's not something your being scored on and it's not a critical service for you to access the machine then shut it down. Further, you should try to restrict your access paths to whitelisted hosts or locations that only you control, this type of whitelisted access as opposed to blocking red team IPs is very effective in a competition like this. It took awhile, but network firewall rules and locking down to specific services was a huge benefit that killed much of our persistence and callbacks. Teams that do this are usually highly successful.
This year I took an interesting approach and used some dev-ops / host management tools as C&C! The premise was to deploy a
salt stack framework as a proof of concept test, to see if the students would recognize the host management framework hiding in plane sight, yet allow it to continue, not knowing if it was part of their environment or the attackers. In the end it was extremely successful, not only did they see it and investigate it, but they still allowed the services to run for much of the competition. The lesson here for blue teams' is even if a service looks legitimate or isn't 'malware', make sure it's truly your infrastructure, the way you configured it, and operating with integrity. The salt stack was also very useful in managing which machines I still had control of and for running commands across them in groups. While I also had a salt minion payload prepared for Linux it didn't integrate to our Linux dropper as well, therefore that one was not deployed as ubiquitously.



Spend the time to look at your logs and do some root cause analysis. So many times the teams would revert the machine in an attempt to quickly keep the service availability up, but without fixing the underlying vulnerability. This allowed the red team to continue exploiting the machines and shutting the services down, causing them to loose far more time in service availability than if the blue team just took the upfront cost and spent the time doing the analysis to kick us out. This is
as Dave called it in the Red Team Debrief, reacting and not responding.
Understanding your dedicated attackers' techniques and operations can help you to block them on similar systems, as well look for their specific indicators of compromise. If you catch someone using an oddly specific technique than look for it's artifacts on other machines, as this could be a clear indication that your operating on a compromised server or not. Finally, a few defacement photos for the lols, because after all we are here to learn and have fun.