libc++'s Implementation of std:string
I. Introduction
libc++ is the LLVM project’s implementation of the C++ standard library. libc++’s implementation of std::string is a fascinating case study of how to optimize container classes. Unfortunately, the source code is very hard to read because it is extremely:
- Optimized. Even for relatively niche use-cases.
- General. The
std::stringclass is a specialization ofbasic_string.basic_stringcan accept a custom character type and custom allocator. - Portable. This leads to
#ifdefmacros everywhere. - Resilient. Every non-public identifier is prefixed with underscores to prevent name clashes with other code. This is necessary even for local variables since macros defined by the user of the library could modify the library’s header file.
- Undocumented. There are very few comments in the
This post examines the implementation of libc++’s std::string. To keep it simple I will assume you are using a modern compiler and a modern x86 processor1. Keep in mind that the way objects are laid out in memory is very specific to the compiler, CPU archictecture and standard library used; everything I describe below is an implementation detail and not defined by the C++ standard.
II. Data layout
std::string has two modes: long string and short string. It uses a union to reuse the same bytes for both modes. Short string mode is an optimization which makes it possible to store up to 22 characters without heap allocation.
Long string mode
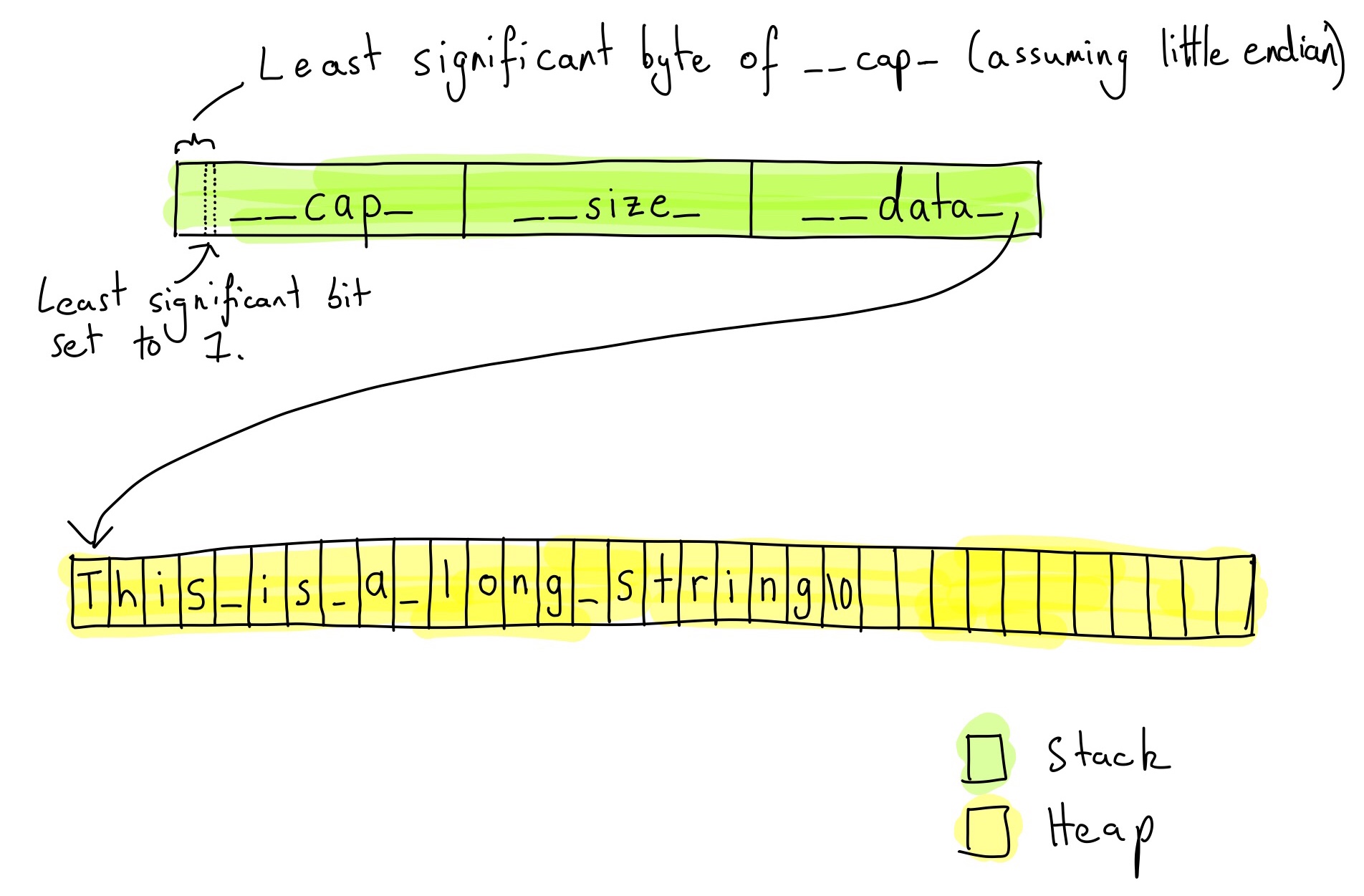
The long string mode is a pretty standard string implementation. There are three members:
size_t __cap_- The amount of space in the underlying character buffer. If the string grows enough that length of the string (including the null-terminator) exceeds__cap_then the buffer must be reallocated.__cap_is an unsigned 64 bit integer. The least significant bit of__cap_is used as a flag, see the discussion below.size_t __size_- The size of the current string, not including the null terminator. This is also an unsigned 64 bit integer.char* __data_- A pointer to the underlying buffer where the characters of the string are stored. This is 64 bits wide.
Since each member is 8 bytes, sizeof(std::string) == 24.
std::string uses the least significant bit of __cap_ to distinguish whether it is in long string mode or short string mode. If the least significant bit is set to 1, then it is in long string mode. If it is set to zero, then it is in short string mode. It is possible to use the least significant bit in this way because the size of the buffer is guaranteed by the implementation to always be an even number - so the true value for the capacity always has a 0 in the least significant bit. The method std::string::capacity() has an implementation that is equivalent to this (the real code looks quite different):
size_t capacity() const noexcept { if (__cap_ & 1) { // Long string mode. // buffer_size holds the true size of the underlying buffer pointed // to by data_. The size of the buffer is always an even number. The // least significant bit of __cap_ is cleared since it is just used // as a flag to indicate that we are in long string mode. size_t buffer_size = __cap_ & ~1ul; // Subtract 1 because the null terminator takes up one spot in the // character buffer. return buffer_size - 1; } // } Short string mode
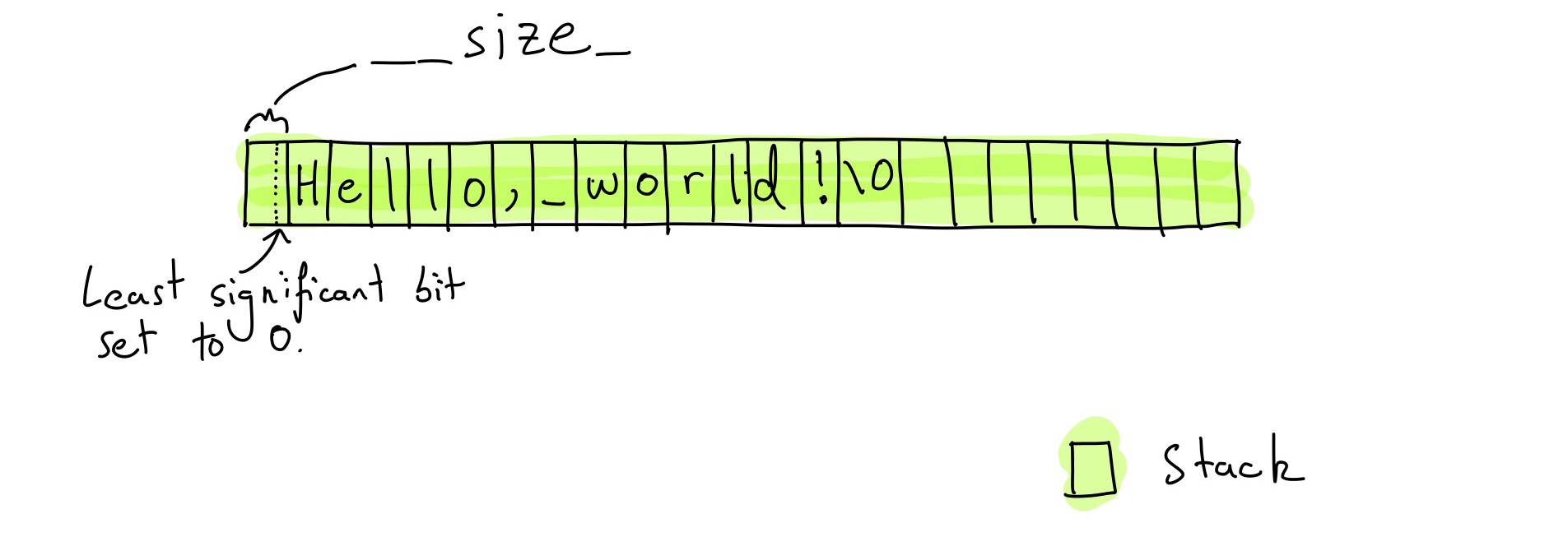
The short string mode uses the same 24 bytes to mean something completely different. There are two members:
unsigned char __size_- The size of the string, left-shifted by one (__size_ == (true_size << 1)). The true size of the string is left-shifted by one because the least significant bit of the first byte is used as a flag. The least significant bit must be set to 0 in short string mode.char __data_[23]- A buffer to hold the characters of the string.
__size_ stores the size of the string left shifted by 1, so the method std::string::size() has an implementation equivalent to this:
size_t size() const noexcept { if (__size_ & 1u == 0) { // Short string mode. return __size_ >> 1; } // } Because we are assuming the target architecture is little-endian, the least significant bit of __cap_ is in the same position as the least significant bit of __size_.
III. Implementation
To see how the libc++ implementation achieves the data layout described above, I’m going to copy and paste real code snippets from libc++ and add comments.
Long mode is reasonably straightforward, it’s implemented like this:
// size_type and pointer are type aliases. struct __long { size_type __cap_; size_type __size_; pointer __data_; }; Short mode looks like this:
static const size_type __short_mask = 0x01; static const size_type __long_mask = 0x1ul; enum { __min_cap = (sizeof(__long) - 1) / sizeof(value_type) > 2 ? (sizeof(__long) - 1) / sizeof(value_type) : 2 }; struct __short { union { unsigned char __size_; value_type __lx; }; value_type __data_[__min_cap]; }; According to this Reddit comment, __lx is needed to ensure any padding goes after __size_, but has no other purpose (I don’t fully understand why this forces the padding to go after __size_ 🤷♂). __min_cap is 23 on the platforms we are considering (64-bit).
So the first byte of __short is occupied by __size_, and the next 23 are occupied the __data_ array.
The string is then represented like this:
// __ulx is only used to calculate __n_words. union __ulx { __long __lx; __short __lxx; }; enum { __n_words = sizeof(__ulx) / sizeof(size_type) }; struct __raw { size_type __words[__n_words]; }; struct __rep { union { __long __l; __short __s; __raw __r; }; }; The __rep_ struct represents the string. It is a union of __long and __short as expected.
The __raw struct is just an array of size 24 which allows some of the methods to consider the string as a sequence of bytes without having to care about whether the string is in long or short mode. For example, after a string is moved-from it is zeroed out, and the __zero() method is implemented like this:
void __zero() noexcept { size_type (&__a)[__n_words] = __r_.first().__r.__words; for (unsigned __i = 0; __i < __n_words; ++__i) __a[__i] = 0; } Finally, the only member variable in std::string is declared like this:
// allocator_type is the allocator defined by the user of basic_string __compressed_pair<__rep, allocator_type> __r_; __compressed_pair behaves like std::pair, except it has an optimization where if one of the templates in the pair is an empty class then that class will not contribute to the size of the pair. std::pair is larger than it needs to be, for example:
#include #include struct E {}; int main() { std::pair p; std::cout << sizeof(int) << std::endl; // Outputs 4. std::cout << sizeof(E) << std::endl; // Outputs 1. std::cout << sizeof(p) << std::endl; // Outputs 8. std;:cout << sizeof(__compressed_pair) << std::endl; // Outputs 4. } The reason E uses any space in the example above is for language-technical reasons: every object must have a unique memory address. (This will change in C++20, see here and here.) std::pair stores the objects next to each other in memory, and padding means that the E struct in the example above contributes 4 bytes to the pair.
__compressed_pair will not use any extra space if allocator_type is empty.
And that’s all there is to it! The implementation of std::string looks like this (with #ifdefs removed):
template class _LIBCPP_TEMPLATE_VIS basic_string : private __basic_string_common { // private: struct __long { size_type __cap_; size_type __size_; pointer __data_; }; static const size_type __short_mask = 0x01; static const size_type __long_mask = 0x1ul; enum { __min_cap = (sizeof(__long) - 1) / sizeof(value_type) > 2 ? (sizeof(__long) - 1) / sizeof(value_type) : 2 }; struct __short { union { unsigned char __size_; value_type __lx; }; value_type __data_[__min_cap]; }; union __ulx { __long __lx; __short __lxx; }; enum { __n_words = sizeof(__ulx) / sizeof(size_type) }; struct __raw { size_type __words[__n_words]; }; struct __rep { union { __long __l; __short __s; __raw __r; }; }; __compressed_pair<__rep, allocator_type> __r_; public: // }; // In another file: typedef basic_string string; Here is the full source on GitHub if you want to take a look.
1 In particular, I will assume that (1) you are using the standard ABI layout, (2) your computer is 64-bit and little endian and (3) the char type is signed and 1 byte wide. (There may be something else I missed. In practice I’m just assuming the layout on your machine is the same as on my machine.) ↩
from Hacker News https://ift.tt/2vBsXvL